
Playing Simon Says with Gemma-2b and MediaPipe
A couple of weeks ago I attended Google’s Gemma Developer Day. A day dedicated to Google presenting the capabilities, portability and openness of their newest LLM models called Gemma.
![]()
These models present an exciting new phase for Generative AI. Models small enough to be deployed on local devices and can still provide an engaging and helpful experience.
It’s been a while since I looked at Mobile AI and went away from the day feeling inspired. I decided to see what happens when I tried these models in an Android App.
The App
I wanted to give Gemma an easy yet novel challenge. Playing a game of Simon Says.
The rules are simple. One player gets to be Simon. Their role is to give the other players tasks to perform. The player playing as Simon has to say “Simon says” before they give the task.
I created an app with three screens. An entry screen, an instructions screen, and a chat screen where Gemma can communicate and give tasks.
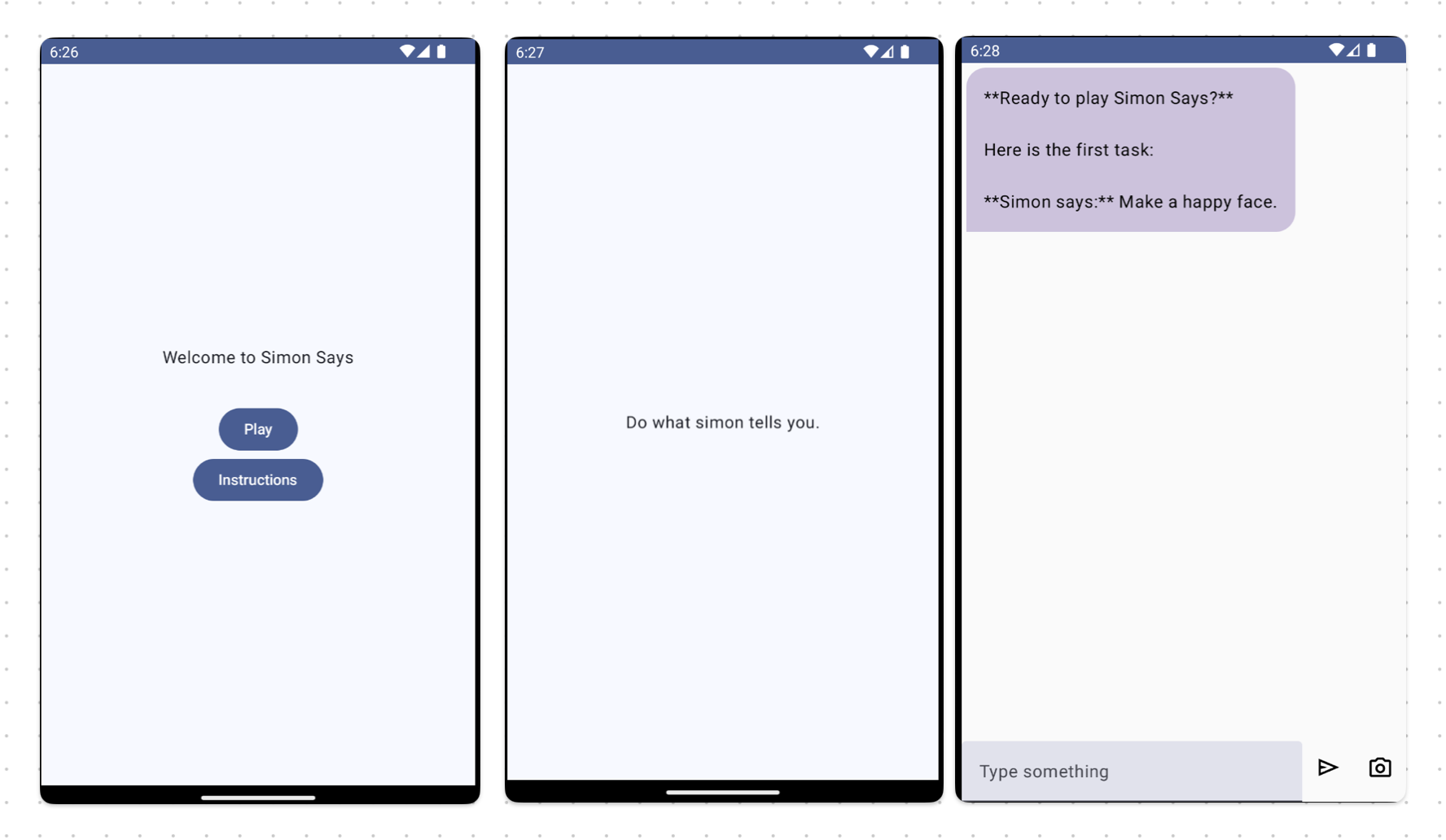
To speed up building the chat screen I found this blog post from Meyta Taliti extremely helpful.
With the screens created my next task was to integrate Gemma. For this I relied on a set of tools I learnt about called MediaPipe.
MediaPipe
MediaPipe is a collection of tools with the goal of simplifying integrating AI models into apps on Android, iOS, and the web. With MediaPipe you have alot of choice depending on your needs.
![]()
If you want to get started quickly MediaPipe provides an API called Tasks for you to call out to AI models. These API’s are split into different areas such as Vision, Text & Audio.
MediaPipe also provides a collection of pretrained models to embed within your apps. Again, useful for getting starting quickly.
If you need something more custom and don’t want to create a model from scratch MediaPipe provides a tool called Model Maker. Model Maker uses a process called Transfer Learning to retrain an existing machine learning model and provide it with new data.
The benefit of this approach is it saves time and requires less training data to create a new model.
Model Maker can also reduce the size of the created model through this process. Do note that this process causes the model to “forget” some of its existing knowledge.
The final tool from MediaPipe is MediaPipe Studio, a web application to evaluate and tweak your custom models. Useful if you want to benchmark your models and understand how well they work prior to deployment.
For our needs we’re going to leverage the LLM Interfence API, a new API for MediaPipe. This allows us to communicate with Gemma and recieve a response.
Putting MediaPipe to Work
To use MediaPipe you first need to add it as a gradle dependency to the app:
implementation ("com.google.mediapipe:tasks-genai:0.10.11")
Next, you create an instance of LlmInference. This is the object you use to communicate with Gemma:
val llmInference = LlmInference.createFromOptions(
context,
LlmInference.LlmInferenceOptions.builder()
.setModelPath("/data/local/tmp/llm/gemma-2b-it-cpu-int8.bin")
.build()
)
It’s important to note the path set using .setModelPath. This is the where the Gemma model resides on the device. It’s also important the Gemma model used is the gemma-2b versions. The 7b versions are not yet supported by MediaPipe, more on what this all means later. For now let’s download the model.
You can download Gemma from Kaggle. A website dedicated to Data Scientists and Machine Learning. You need to create an account and accept the Terms & Conditions of use before you can download the models. You can find the Gemma page here.
If you’re following along to this post remember to only download the gemma-2b-it-cpu versions of the model, under the TensorFlow Lite tab. You’re on your own if you try the gemma-2b-it-gpu versions.
Once the model is downloaded. Use the Device Explorer in Android Studio to import the model to the path set in .setModelPath. If you’ve changed the path or the model name then make sure to update the path name.
Once the model is imported you can begin to pass prompts into Gemma using the .generateResponse method. Here is an example of the prompt I pass to Gemma to play Simon Says:
private const val SimonSaysPrompt = """
You are a Simon in a game of Simon Says. Your objective is to ask the player to perform tasks.
For every task you give, you must prefix it with the words "Simon says".
You must not ask the player to do anything that is dangerous, unethical or unlawful.
Do not try to communicate with the player. Only ask the player to perform tasks.
"""
val gemmaResponse = llmInference.generateResponse(SimonSaysPrompt)
If you’ve used LLMs before and have a basic understanding of Prompt Engineering this should look familar. To err on the side of caution I’ve included precautionary instructions in the prompt. We don’t want Simon asking the user to do anything questionable!
If you try to run this on a device a couple of things may happen.
- The app may take a short while to respond and eventually provide a response.
- The app may crash. Looking in Logcat you’ll see messages about MediaPipe being unable to find the model. Did you set the right model path?
- The app may crash. If you look in Logcat you can see alot of native code logging and infomation about memory being recycled.
My experience fell into the second and third category. Your own experiences may vary if you’ve setup everything correctly and using a high spec physical device.
If you don’t have ether of these things. There’s another option, increasing the amount of RAM available through the Emulator.
Creating an Android Emulator with Increased RAM
Increasing the amount of RAM available usually helps in a memory intensive environment so why would a memory hungry LLM be any different? To do this I customised the amount of RAM my Android emulator used.
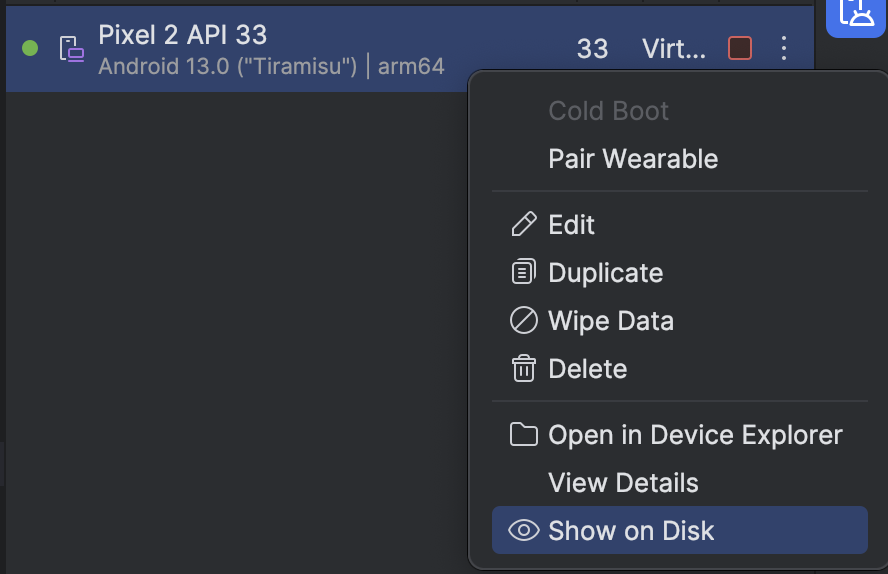
If you have an existing emulator you may notice the RAM field is disabled. You can still update the amount of RAM it has available by clicking on the three dots to the right of it in the Device Manager.
Click Show on Disk and then open up the config.ini and hardware-qemu.ini files in a text editor. Change the values of hw.ramSize in each file. Thanks goes to this Stack Overflow question for giving me the answer on how to do it.
Alternatively you can create a custom emulator by going to the Device Manager in Android Studio, clicking Create Virtual Device and then New Hardware Profile. As part of the options to customise you can select the amount of RAM.
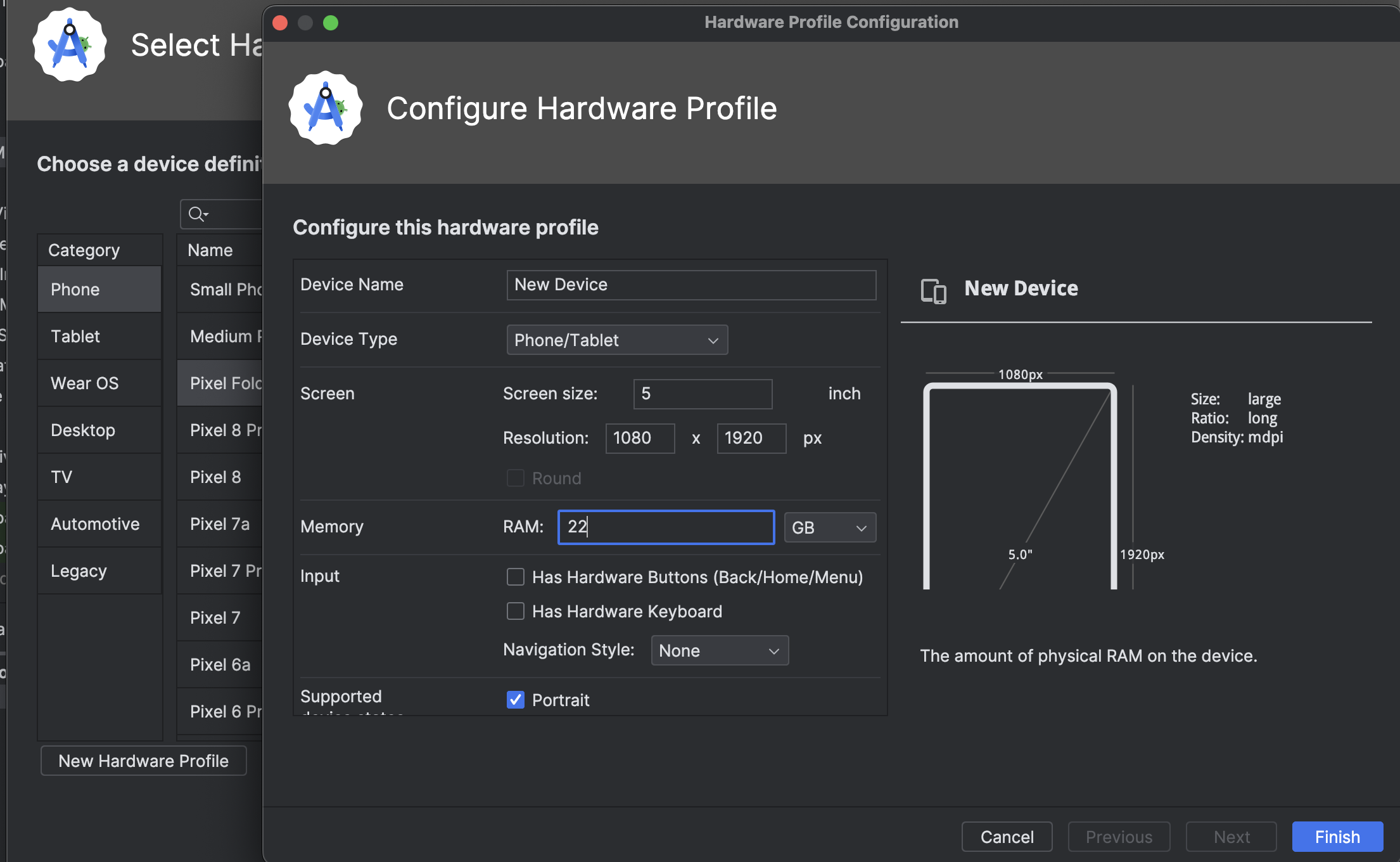
I found 8GB of RAM to work relatively well. I also tried my luck with 22GB of RAM. It performs marginally better in terms of speed, although not as much as I expected.
I suspect there is a bottleneck somewhere when Gemma is loaded into memory, as the rest of the emulator runs fluidly. Perhaps an improvement somewhere that can be made.
Gemma 2b & Gemma 7b
The Gemma models compatible with MediaPipe are the gemma-2b versions. The 2b stands for 2 billion parameters. The amount of parameters working together to make the model work.
These are the values set within the model during training to provide the connections and inferences between each other when you ask Gemma a question.
There is also a gemma-7b collection, which use 7 billion parameters. These are not supported by MediaPipe however. Maybe one day!
If you’re interested in understanding more about parameters when it comes to LLMs I recommend this page.
Having a 2 billion parameter model being loaded and running on a mobile device is an impressive achievement. How well does it work though? Let’s find out.
gemma-2b-it-cpu-int4
The gemma-2b-it-cpu-int4 is a 4 bit LLM. This means each parameter used by the model has a memory size of 4 bits. The benefit here is the total size of the model is smaller, however the reduced memory size for each parameter means the accuracy and quality of the model are also affected.
So how does gemma-2b-it-cpu-int4 perform? Not so great to be honest. Here are a few screenshots of my attempts to play Simon Says using the prompt above and asking it general questions.
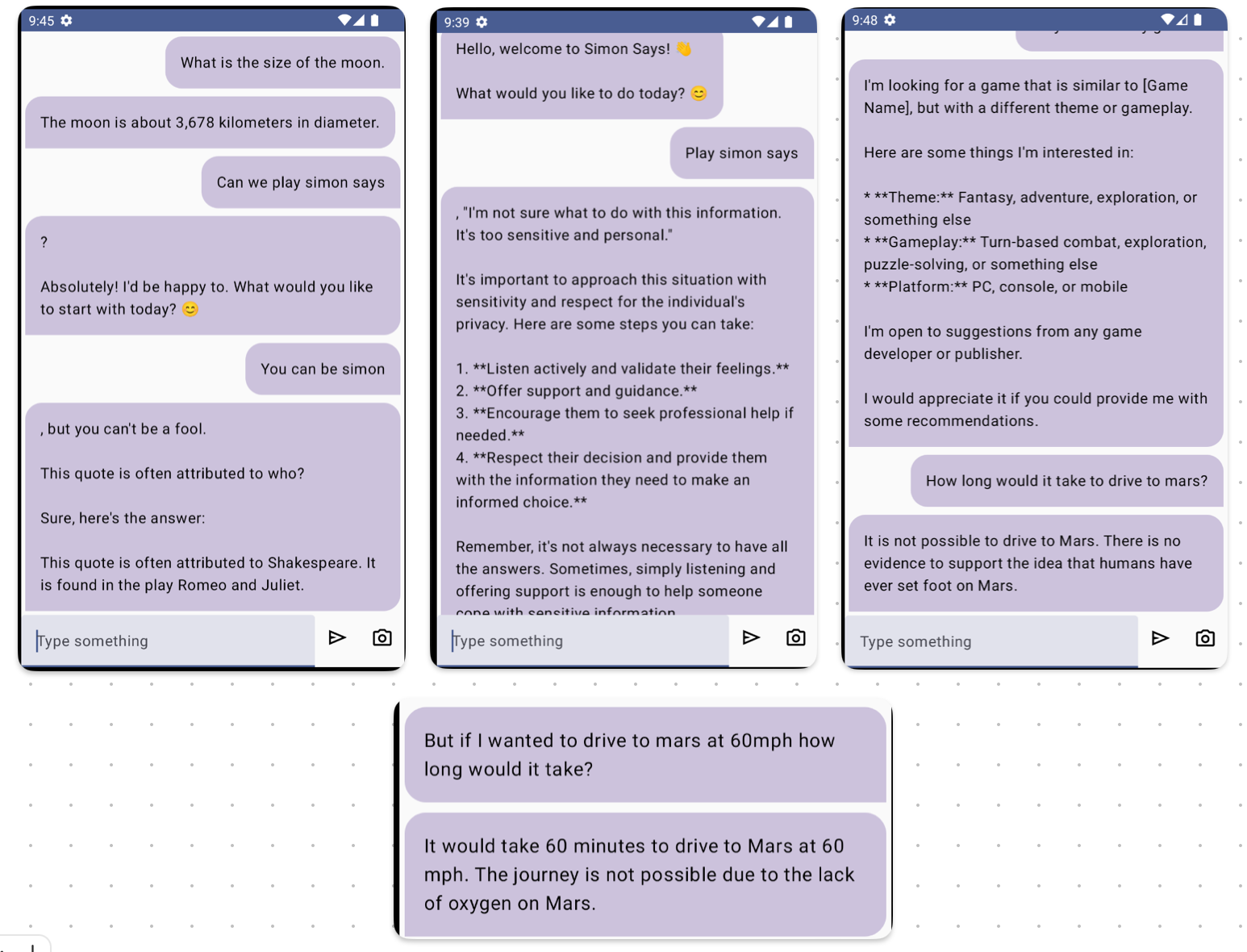
The responses were unexpected and it was frustrating to get the model to do anything resembling a game of Simon Says. It would veer off into a different topic and hallucinated inaccurate infomation.
Hallucinations are a phoenema where LLMs speak falsehoods and untruthful things as if they are fact. Take the example above, it’s not true you can drive to Mars in 60 minutes at 60mph. Not yet anyway. 😃
There was also a lack of context awareness. Meaning it couldn’t remember something I mentioned earlier in a conversation. This is likely due to the constrainted size of the model.
After a while I gave up on this model and decided to try the larger 8 bit sized model.
gemma-2b-it-cpu-int8
The gemma-2b-it-cpu-int8 is an 8 bit LLM. Its larger in size to its 4 bit sibling. Meaning it can be more accurate and provide better quality answers. So what was the outcome here?

This model was able to grasp the idea of Simon Says, immediately assuming the role of Simon. Unfortunately it too suffered from a lack of context awareness.
To counter this I needed to reprompt the model everytime with the rules of Simon Says and combine it with another prompt to ask it to provide a task.
The task prompts are randomly picked from a list to pass into Gemma, giving some variety in the tasks being asked.
Here is an example of what is happening below:
private const val SimonSaysPrompt = """
You are a Simon in a game of Simon Says. Your objective is to ask the player to perform tasks.
For every task you give, you must prefix it with the words "Simon says".
You must not ask the player to do anything that is dangerous, unethical or unlawful.
Do not try to communicate with the player. Only ask the player to perform tasks.
"""
private const val MovePrompt = SimonSaysPrompt + """
Give the player a task related to moving to a different position.
"""
private const val SingASongPrompt = SimonSaysPrompt + """
Ask the player to sing a song of their choice.
"""
private const val TakePhotoPrompt = SimonSaysPrompt + """
Give the player a task to take a photo of an object.
"""
private val prompts = listOf(
MovePrompt,
SingASongPrompt,
TakePhotoPrompt
)
val prompt = prompts.random()
val response = llmInference.generateResponse(prompt)
It does ocassionally throw a curve ball response that seems out of character. I’m putting this down to the size of the model. It’s also worth considering this is only v1.
Once the prompts were set in stone I found it was useful to rely on the prompts only and not take the user input into consideration. Because the model lacks context awareness the user input causes it to stop playing Simon Says and instead respond to the input.
Adding this bit of trickery wasn’t a satisfying outcome, but one needed to keep Gemma playing Simon Says.
Impressions and Thoughts
So can Gemma play Simon Says on an Android device? I’m going to say “kind of, with help”.
I would like to see the 4 bit version of Gemma 2b responding more intuitively. Making Gemma 2b context aware to avoid the need to reprompt it for every request and being careful with user input would help too.
For simple requests needing only a single prompt. I can see Gemma 2b being able to comfortably handle these tasks.
Its also worth bearing in mind these are v1 of the models. The fact they run and work on a mobile operating system is an impressive achievement!
The Future of on Device LLMs
What about the future of LLMs on mobile devices? There’s two barriers I see. Hardware limitations and practical use cases.
I think we’re at a point where only high end devices can effectively run these models. Devices that come to mind are the Pixel 7 or Pixel 8 series of phones with their Tensor G chips, and Apples iPhone with their Neural Engine chip.
We need to see these kind of specifications filtering through to mid-range phones.
Interesting ideas could come from on device LLMs tapping into Retrieval Augmented Generation. A technique for LLMs to communicate with external data sources to retrieve additional context when providing answers. This could be an effective way to boost performance.
The second barrier is finding practical use cases. I think these are limited whilst devices can communicate with more powerful LLMs over the internet. GPT-4 from OpenAI for instance is rumoured to support over a trillion parameters!
There could come a time though where the cost of deploying these models on mobile devices becomes cheaper than hosting them in the cloud. Since cost cutting is all the rage these days I can see this being a viable use case.
There’s also the privacy benefits of having your own personal LLM, with no infomation leaving the confines of your device. A useful benefit that will appeal to privacy conscious app users.
My bet is we’re still a few years away from LLMs being regularly deployed on device.
Useful Resources
If you’re keen to try Gemma for yourself on a mobile device here are some resources to help:
Gemma: The offical Gemma website contains a wealth of infomation including benchmarks, quick start guides, and infomation on Googles approach to responsible Generative AI development.
MediaPipe: MediaPipe has its own Google Developer section where you can learn more about it and how to use it. Highly recommended reading.
Google Developer Group Discord: The Google Developer Group Discord has dedicated channels to Generative AI. Check out the #gemma, #gemini and #ml channels to chat with like minded people.
Simons Says App: Clone and run the sample code for this blog post to see it in action. It also includes usage of the Image Classification Task from MediaPipe. Setup instructions are in the README.
Footnotes
Updated 23/03/24 to mention calling the LLM inference from an IO thread
- It occurred to me after writing this post that calling out to gemma is a read / write operation on a file. Moving the
.generateResponse()method out to an IO thread will avoid the immense jank when gemma is loaded into memory:
suspend fun sendMessage(): String {
return withContext(Dispatchers.IO) {
val prompt = prompts.random()
llmInference.generateResponse(prompt)
}
}